A single TelePresence camera configured for 1080p best resolution can send up to approximately 4 Mbps of video traffic at peak rate. With an average of 1100 bytes per packet, this yields approximately 455 packets per second. However, with normal motion, each camera typically generates somewhere between 3 Mbps to 3.5 Mbps of video; yielding a packet rate between 340 packets to 400 packets per second. Likewise a single TelePresence microphone generates a voice packet of roughly 220 bytes every 20 msec. Thisyields a voice packet rate of approximately 50 packets per second. The audio rate is fixed regardless of the amount of speaking going on within the meeting. Therefore under normal motion, a TelePresence endpoint with one cameras and one microphone (such as the CTS-1000 or CTS-500) typically generates approximately 390 packets to 450 packets per second. Likewise, under normal motion, a TelePresence endpoint with three cameras and three microphones (such as the CTS-3000) typically generates approximately 1170 packets to 1350 packets per second. Note that this does not include the use of the auxiliary video and audio inputs, voice and video interoperability with legacy systems, and any signaling and management traffic; all of which increase the packet rate.
Multiplexing
The underlying transport protocol for RTP is not specified within RFC 3550. However, RTP and RTCP are typically implemented over UDP. When implemented over UDP, the port range of 16384 to 32767 is often used. RTP streams often use the even-numbered ports, with their accompanying RTCP streams using the next higher odd-numbered port. In this case, RTP sessions are identified by a unique destination address pair that consists of a network address plus a pair of ports for RTP and RTCP. Cisco TelePresence endpoints are capable of both sending and receiving multiple audio and video streams. The primary codec multiplexes these streams together into a single audio RTP stream and a single video RTP stream. Multiplexing is accomplished through the use of different Synchronization Source Identifiers (SSRC), for each video camera and each audio microphone, including the auxiliary inputs. In the case of Cisco TelePresence, SSRCs indicate not only the source position of the audio or video media, but also the destination position of the display or speaker to which the media is intended. Therefore, the receiving primary codec can demultiplex the RTP session and send the individual RTP streams to the appropriate display or speaker. This is how spatial audio is achieved with TelePresence and how video display positions are maintained throughout a TelePresence meeting.
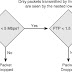
When endpoints join a multipoint call, they first attempt to exchange RTCP packets. Successful exchange of these packets indicates the opposite endpoint is a Cisco TelePresence device, capable of supporting various Cisco extensions. Among other things, these extensions determine the number of audio and video channels each TelePresence endpoint can send and receive and their positions. Audio and video streams are sent and received based on their position within the CTS endpoint, which is then mapped to a corresponding SSRC. Figure 1 shows an example for a three-screen endpoint, such as a CTS-3000, communicating with a CTMS.

Each CTS-3000 or CTS-3200 can transmit (and receive) up to four audio streams and four video streams from the left, center, right, and auxiliary positions. These correspond to the left, center, and right cameras, microphones, and the auxiliary input. Therefore, in a point-to-point meeting between CTS-3000s or CTS-3200s, there can be as many as four audio SSRCs multiplexed together in a single audio RTP stream and four video SSRCs multiplexed together in a single video RTP stream sent from each endpoint.
As Figure 1 illustrates, the CTMS can transmit up to four video streams, corresponding to the left, center, and right displays of the CTS-3000 or CTS-3200, and either a projector or monitor connected to the auxiliary video output. However, the CTMS transmits only up to three audio streams, corresponding to the left, center, and right speaker positions of the CTS-3000 or CTS-3200. Audio sent by an originating CTS-3000 or CTS-3200 toward the auxiliary position is redirected to one of the three speaker positions of the destination CTS-3000 or CTS-3200 by the CTMS. The CTMS chooses the three loudest audio streams to send to the remote CTS-3000 or CTS-3200 when there are more than three streams with audio energy.
Figure 2 shows the audio and video positions for a multipoint call consisting of CTS-1000s or CTS-500s.

Each CTS-1000 or CTS-500 can transmit up to two audio streams and two video streams from the center and auxiliary positions. These correspond to the single camera and microphone of the CTS-1000 or CTS-500, and the auxiliary input. Therefore, in a point-to-point meeting between CTS-1000s or CTS-500s there can be as many as two audio SSRCs multiplexed together in a single audio RTP stream and two video SSRCs multiplexed together in a single video RTP stream sent from each endpoint.
As Figure 2 illustrates, the CTMS can still transmit up to three audio streams, corresponding to the left, center, and right microphone positions of the CTS-3000 or CTS-3200, even though the CTS-1000 or CTS-500 have only a single speaker. The CTS-1000 or CTS-500 mixes the audio from each of the three positions to play out on its single speaker. The CTS-1000 or CTS-500 can receive only up to two video streams, corresponding to the center display and picture-in-picture auxiliary video output.
RTP Control Protocol
The RTP Control Protocol (RTCP) provides four main functions for RTP sessions:
- Provides feedback on the quality of the distribution of RTP packets from the source.
- Carries a persistent transport-level identifier called the canonical name (CNAME), which associates multiple data streams from a given participant in a set of RTP sessions.
- Provides a feedback mechanism to scale the actual use of RTCP itself. Because all participants send RTCP packets, the rate of arrival of RTCP packets can determine the number of participants and the rate at which RTCP packets should be sent so that the network is not overwhelmed by RTCP packets.
- Can be optionally used to convey minimal session control information between participants.
Several different RTCP packets packet types convey the preceding information. These include a Sender Report (SR), Receiver Report (RR), Session Descriptor (SDES), and Application Specific (APP) packets; among others. Typically RTCP sends compound packets containing combinations of these reports in a single packet.
As mentioned previously, each RTP stream has an accompanying RTCP stream. These RTCP streams can be sent using the next higher odd-numbered port or optionally multiplexed in with the RTP streams themselves. Initial TelePresence software versions multiplexed in the RTCP streams within the RTP streams. For interoperability, current TelePresence software versions support both options. RTCP signals packet loss within TelePresence deployments, causing the sender to send a new reference frame (IDR) to resynchronize the video transmission. Additionally, RTCP is used between TelePresence endpoints to inform each other of the number of audio and video channels they are capable of supporting. The number of channels corresponds to the number of displays, cameras, microphones, and speakers supported by the particular endpoint. Finally, the Cisco TelePresence Multipoint Switch (CTMS) uses RTCP packets to perform session control within multipoint calls. The CTMS informs TelePresence endpoints that do not have active speakers to stop transmitting video. When a particular table segment or room has an active speaker, the CTMS detects this through the audio energy and informs the table segment or room, through RTCP packets, to send video.









No comments:
Post a Comment