Cisco Gateway Load Balancing Protocol (GLBP) improves the efficiency of FHRP protocols by allowing for automatic load balancing of the default gateway. The advantage of GLBP is that it additionally provides load balancing over multiple routers (gateways) using a single virtual IP address and multiple virtual MAC addresses per GLBP group. (In contrast, both HRSP and VRRP used only one virtual MAC address per HSRP/VRRP group.) The forwarding load is shared among all routers in a GLBP group rather than handled by a single router while the other routers stand idle. Each host is configured with the same virtual IP address, and all routers in the virtual router group participate in forwarding packets.
Members of a GLBP group elect one gateway to be the active virtual gateway (AVG) for that group. Other group members provide backup for the AVG if that AVG becomes unavailable. The function of the AVG is that it assigns a virtual MAC address to each member of the GLBP group. Each gateway assumes responsibility for forwarding packets sent to the virtual MAC address assigned to it by the AVG. These gateways are known as active virtual forwarders (AVF) for their virtual MAC address.
The AVG is also responsible for answering Address Resolution Protocol (ARP) requests for the virtual IP address. Load sharing is achieved by the AVG replying to the ARP requests with different virtual MAC addresses (corresponding to each gateway router).
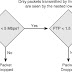
In Figure 1, Router A is the AVG for a GLBP group and is primarily responsible for the virtual IP address 172.16.128.3; however, Router A is also an AVF for the virtual MAC address 0007.b400.0101. Router B is a member of the same GLBP group and is designated as the AVF for the virtual MAC address 0007.b400.0102. All hosts have their default gateway IP addresses set to the virtual IP address of 172.16.128.3. However, when these are an ARP for the MAC of this virtual IP address, Host A and Host C receives a gateway MAC address of 0007.b400.0101 (directing these hosts to use Router A as their default gateway), but Host B and Host D receive a gateway MAC address 0007.b400.0102 (directing these hosts to use Router B as their default gateway). In this way the gateway routers automatically load share.

If Router A becomes unavailable, Hosts A and C do not lose access to the WAN because Router B assumes responsibility for forwarding packets sent to the virtual MAC address of Router A and for responding to packets sent to its own virtual MAC address. Router B also assumes the role of the AVG for the entire GLBP group. Communication for the GLBP members continues despite the failure of a router in the GLBP group.
Additionally, like HSRP and VRRP, GLBP supports object tracking and preemption and SSO awareness.
| Note |
SSO awareness for GLBP is enabled by default when the route processor’s redundancy mode of operation is set to SSO (as was shown in the “NSF with SSO” section of this chapter).
|
However, unlike the object tracking logic used by HSRP and VRRP, GLBP uses a weighting scheme to determine the forwarding capacity of each router in the GLBP group. The weighting assigned to a router in the GLBP group can be used to determine whether it forwards packets and, if so, the proportion of hosts in the LAN for which it forwards packets. Thresholds can be set such that when the weighting for a GLBP group falls below a certain value, and when it rises above another threshold, forwarding is automatically reenabled.
The GLBP group weighting can be automatically adjusted by tracking the state of an interface within the router. If a tracked interface goes down, the GLBP group weighting is reduced by a specified value. Different interfaces can be tracked to decrement the GLBP weighting by varying amounts.
Example 1 shows a GLBP configuration that can be used on the LAN interface of the AVG from Figure 1. Each GLBP group on a given subnet requires a unique number; in this example the GLBP group number is set to 10. The virtual IP address for the GLBP group is set to 172.16.128.3. The GLBP priority of this interface has been set to 105, and like HSRP, preemption for GLBP must be explicitly enabled (if desired). Finally, object tracking has been configured so that should the line protocol state of interface Serial0/1 go down (the WAN link for this router, which is designated as object-number 110), the GLBP priority for this interface dynamically decrements (by a value of 10, by default).
Example 1: GLBP Example
Router(config)# track 110 interface Serial0/1 line-protocol Router(config)# interface GigabitEthernet0/0 Router(config-if)# ip address 172.16.128.1 255.255.255.0 Router(config-if)# glbp 10 ip 172.16.128.3 Router(config-if)# glbp 10 priority 105 Router(config-if)# glbp 10 preempt Router(config-if)# glbp 10 weighting track 110