As previously discussed, Cisco TelePresence uses a multiplexing technique, using the SSRC field of the RTP header, to transport multiple video and audio channels over RTP. Each call (session) consists of two RTP streams: one for video and one for audio. On single-screen systems, the video RTP stream consists of two video channels: one for the Cisco TelePresence camera and one for the auxiliary (PC or document camera) video inputs. Likewise, the audio RTP stream consists of two audio channels: one for the Cisco TelePresence microphone and one for the auxiliary (PC) audio input. On multiscreen systems, the video RTP stream consists of four video channels, and the audio RTP stream consists of four audio channels.
Video and Audio Output Mapping
These channels must be demultiplexed, decoded, and played out the corresponding output (to the appropriate screen for video and to the appropriate speaker for audio). Because the entire TelePresence system connects to the network using a single 1000Base-T Gigabit Ethernet interface, all the packets are received by the primary (center) codec. The primary codec analyzes the SSRC field of the RTP headers and sends the left video channel to the left secondary codec and the right video channel to the right secondary codec. The primary codec then proceeds to buffer and decode the center and auxiliary video packets and all audio packets, and the two secondary codecs buffer and decode their respective video packets.
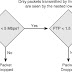
Figure 1 illustrates how these channels are mapped from the transmitting TelePresence codec to the receiving TelePresence codec.

Figure 1: Video and audio output mapping
| Note | Figure 1 illustrates a multiscreen system. Single-screen systems would behave exactly the same way, except that the left and right channels would not be present. |
Display Outputs, Resolution, and Refresh Rate (Hz)
The left, center, and right video channels are decoded by each Cisco TelePresence codec and sent out the corresponding HDMI interface to the left, center, and right displays. At the time this book was written, the CTS-1000, CTS-3000, and CTS-3200 use 65-inch plasma displays, whereas the CTS-500 uses a 37-inch LCD display. In all cases, these displays run at 1080p resolution at 60 Hz refresh rate using progressive scan. Therefore, the Cisco TelePresence codec must decode the video (whether it was encoded at 1080p / 30 or 720p / 30) and send it to the display at 1080p / 60.
The auxiliary video channel is also decoded and sent out the auxiliary HDMI interface to either the projector or an auxiliary LCD display or displayed as Presentation-in-Picture(PIP) on the center display. Depending on its destination, the Cisco TelePresence codec decodes the video (which was encoded at 1024x768 at either 5 fps or 30 fps) and sends it out at the correct refresh rate. When it is sent out the auxiliary HDMI interface to either the projector or an auxiliary LCD display, the Cisco TelePresence codec outputs it at 49.5 Hz using interlaced scanning. When it is sent as PIP to the primary HDMI display port, it overlays it on top of the center channels video and outputs it at 1080p / 60.
Frames per Second Versus Fields per Second Versus Refresh Rate (Hz)
It’s worth inserting a quick word here on the difference between frames versus fields versus refresh or scan rates (Hz). These terms are frequently confused in the video conferencing and telepresence industries. (For example, a vendor might state that its system does 60 fields per second.)
In a Cisco TelePresence system, the camera operates at a scan rate (also known as refresh rate or clock rate) of 30 Hz. The codec encodes that video into H.264 video frames at a rate of 30 frames per second (30 fps). The plasma and LCD displays used in Cisco TelePresence operate at a scan rate of 60 Hz using progressive scan display technology. Because the displays are 60-Hz progressive scan, Cisco can claim 60 fields per second support as well. But what actually matters is that the source (the camera) is operating at 30 Hz, and the video is encoded at 30 fps. To truly claim 60 fps, the camera would need to run at 60 Hz, the encoder would need to pump out 60 video frames per second (every 16 ms or so), and the displays would need to run at 120 Hz. This would provide astounding video quality but would also result in double the DSP horsepower and bandwidth needed and quite frankly is unnecessary because the current 30-fps implementation is already the highest-quality solution on the planet and is absolutely adequate for reproducing a true-to-life visual experience.
Instead of getting caught up in a debate over Hz rates and progressive scan versus interlaced scan methods, the most accurate method for determining the true “frame rate” of any vendors’ codec is to analyze their RTP packets. As described earlier in the Real-Time Transport Protocol section, all vendors implementing RTP for video transport use the marker bit to indicate the end of a video frame. Using a packet sniffer, such as the open source program Wireshark (http://www.wireshark.org), and filtering on the RTP marker bit, a graph can be produced with the marker bits highlighted. The x-axis on the graph displays the time those packets arrived and, hence, the number of milliseconds between each marker bit. Dividing 1000 by the number of milliseconds between each marker bit reveals the number of frames per second. With Cisco TelePresence, the marker bits appear every 33 ms (30 fps). With other vendor implementations, which use variable frame-rate encoders, there are much larger and variable times between marker bits. For example, if the time between any two marker bits is 60 ms, the video is only approximately 15 fps for those two frame intervals. If it’s 90 ms, the video is only approximately 11 fps. Because the time between marker bits often varies frame-by-frame in these implementations, you can compute the time between all marker bits to derive an average fps for the entire session.
Figure 2 shows a screenshot of a Wireshark IO Graph of a competitor’s (who shall remain nameless) 720p implementation. In this screenshot, you can see that the RTP packets that have the marker bit set to 0 (false) are colored red (gray in this screen capture), whereas the RTP packets that have the marker bit set to 1 (true) are colored black so that they stand out. The time between the first marker bit on the left (99.839s) and the next marker bit after that (99.878s) is 39 ms (which is approximately 25 fps), whereas the difference between the 99.878s marker bit and the next marker bit after that (99.928s) is 50 ms (20 fps).

Audio Outputs
As discussed previously, the audio from the left, center, and right microphone channels is played out the corresponding left, center, and right speakers. The speakers are mounted underneath each display, except for on the CTS-500 in which case they are mounted above the display because the microphone array is mounted underneath the display. This preserves the directionality and spatiality of the sounds, giving the user the audible perception that the sound is emanating from the correct direction and distance. The auxiliary audio is blended across all the speakers because this source is not actually associated with the left, center, or right positions.
Amplification and Volume
The Cisco TelePresence codec contains an embedded amplifier, and the amplification levels and the wattage of the speakers are closely matched to reproduce human speech and other in-room sounds at the correct decibel levels to mimic, as closely as possible, the volume you would experience if the person were actually sitting that far away in person. This means that the users can speak at normal voice levels. (They never feel like they have to raise their voices unnaturally.)
Acoustic Echo Cancellation
As sound patterns are played out of the speakers, they naturally reflect off of surfaces within the environment (walls, ceilings, floors) and return back to enter the microphones. If these sounds were not removed, people would hear their own voices reflected back to them through the system. Acoustic Echo Cancellation (AEC) is a digital algorithm to sample the audio signal before it plays out of the speakers and creates a synthetic estimate of that sound pattern, then samples the audio coming into the microphones, and when the same pattern is recognized, digitally subtracts it from the incoming audio signal, thereby canceling out the acoustic echo. This sounds simple enough but is complicated by the naturally dynamic nature of sound in various environments. Depending on the structures and surfaces in the room such as tables, chairs, walls, doors, floors, and ceilings, the distance of those surfaces from the microphones, the materials from which those surfaces are constructed, the periodic movement of those surfaces, and the movement of human bodies within the room, and the number of milliseconds the algorithm must wait to determine whether the sound coming into the microphones is echo can vary significantly. Therefore, the algorithm must automatically and dynamically adapt to these changing conditions.
The Cisco TelePresence codec contains an embedded AEC that requires no human tuning or calibration. It is on by default and is fully automatic. In nonstandard environments, where the Cisco TelePresence codecs are used with third-party microphone mixers, you can disable the embedded AEC using the following CLI command:
CTS>set audio aec {enable | disable}









No comments:
Post a Comment