To scale QoS functionality to campus speeds (like Gigabit Ethernet or 10 Gigabit Ethernet), Catalyst switches must perform QoS operations, including queuing, within hardware. For the most part, classification, marking, and policing policies (and syntax) are consistent in both Cisco IOS Software and Catalyst hardware; however, queuing and dropping are significantly different when implemented in hardware. Hardware queuing across Catalyst switches is implemented in a model that can be expressed as1PxQyT, where
1P represents the support of a strict-priority hardware queue (which is usually disabled by default)
xQ represents x number of nonpriority hardware queues (including the default, Best-Effort queue)
yT represents y number of drop-thresholds per nonpriority hardware queue
For example, a Catalyst 6500 48-port 10/100/1000 RJ-45 Module (WS-X6748-GE-TX) has a 1P3Q8T queuing structure, meaning that it has
Traffic assigned to the strict-priority hardware queue is treated with an Expedited Forwarding Per-Hop Behavior (EF PHB). That being said, it bears noting that on some platforms, there is no explicit limit on the amount of traffic that can be assigned to the PQ, and as such the potential to starve nonpriority queues exists. However, this potential for starvation can be effectively addressed by explicitly configuring input policers that limit (on a per-port basis) the amount of traffic that can be assigned to the priority queue (PQ). Incidentally, this is the recommended approach defined in RFC 3246 (Section 3).
Traffic assigned to a nonpriority queue will be provided with bandwidth guarantees, subject to the PQ being either fully-serviced or bounded with input policers.
For most platforms, there are typically multiple, configurable drop-thresholds per nonpriority queue. These are provided to allow for selective dropping policies (discussed in more detail in the next section) and to accommodate intraqueue QoS, which is more important in hardware queuing structures (where the number of queues is few and fixed) than in software queuing structures (where generally-speaking there are more queues available than needed). For example, if a campus network administrator had 12 classes of traffic to provision, yet had to work within a 1P3Q8T queuing structure, he could configure the drop thresholds to provide intraqueue QoS inline with his overall service-level objectives. In other words, he is not constrained to only provision four classes of traffic because that is the total number of queues his hardware supports.
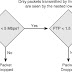
To better understand the operation of a Catalyst hardware queuing, consider a simple example where the hardware supports a 1P2Q2T queuing structure, meaning one strict priority queue, two nonpriority queues each with two configurable drop-thresholds per nonpriority queue. In this example, bandwidth to these queues can be allocated so that Q1 (the default queue) is allocated 85 percent, Q2 (the network control queue) is allocated 10 percent, and Q3 (the priority queue) is allocated 5 percent.
Additionally, consider the use of Weighted Tail Drop (WTD) as the dropping algorithm. In this example, a drop threshold has been configured at 40 percent of Q1’s depth (Q1T1), and another drop threshold has been configured at 40 percent of Q2’s depth (Q2T1). Each queue also has a nonconfigurable drop threshold that corresponds to the tail of the queue (Q1T2 and Q2T2, respectively).
With these queues and thresholds thus provisioned, traffic can be assigned to these queues and thresholds based on CoS values; specifically CoS 5 (representing VoIP) is assigned to Q3, CoS 7 (representing network control protocols, such as Spanning Tree) is mapped to Q2T2, CoS 6 (representing internetworking protocols, such as routing protocols) is mapped to Q2T1, CoS values 2-4 (representing video and data applications) are mapped to Q1T2, and CoS values 0 and 1 are mapped to Q1T1.
Figure 1 illustrates this 1P2Q2T hardware queuing example, with WTD.
As shown in Figure 1, packets marked CoS 5 are assigned to the strict priority queue (Q3) and are serviced ahead of all other traffic. Additionally, packets with CoS values 0
through 4 are assigned on a first-come, first-serve basis to Q1 until Q1T1 is reached. At this point, the queuing algorithm no longer buffers packets marked with CoS values 0 and 1, but drops these; therefore, the remainder of Q1 is exclusively reserved for packets marked to CoS values 2 to 4 (representing higher-priority traffic). Similarly, packets with CoS values 6 and 7 are assigned to Q2, but packets marked CoS 6 are dropped if Q2T1 is exceeded.
Additionally, on some platforms and linecards, queuing is possible not only on egress, but also on ingress. This is because some platforms and linecards are engineered based on oversubscriptions ratios. This engineering approach is often taken as most campus links have average utilization rates far below link capacity and, therefore, can be more economically provisioned for with architectures based on oversubscription.
For example, the Cisco Catalyst 3750G is a fixed-configuration switch that supports up to 48 10/100/1000 ports, plus 4 Small Form-Factor Pluggable (SFP) ports for either GE or 10GE uplinks, representing a (minimum) total input capacity of (48 Gbps + 4 Gbps) 52 Gbps. The backplane of the 3750G is a dual 16 Gbps counter-rotating ring, with a total capacity of 32 Gbps. Thus, this 3750G architecture is engineered with a minimum oversubscription ratio of 52:32 or 13:8 or 1.625:1. However, when 10GE SFP uplinks are used or when (up to 9) 3750G switches are stacked (through Cisco Stackwise technology) into one logical grouping sharing the same dual-ring backplane, the oversubscription ratio becomes much higher. Thus, to protect real-time and critical traffic from being potentially dropped during extreme scenarios, when input rates exceed ring capacity, ingress queuing can be enabled on this platform through a 1P1Q3T queuing structure.
Remember that hardware queuing is (as the name implies) hardware-specific; therefore, there is considerable disparity in ingress and egress queuing structures and feature support
across Catalyst switches platforms. For example, hardware egress queuing structures include the following:
1P3Q3T (Catalyst 2960 and 3560 or 3750)
1P3Q1T (Catalyst 4500 or 4900) and 1P7Q1T, (Catalyst 4500-E or 4900M)
1P2Q1T, 1P2Q2T, 1P3Q1T, 1P3Q8T, 1P7Q4T, and 1P7Q8T (Catalyst 6500, module-dependent)
| Note |
Some older Cisco Catalyst 6500 linecards also support 2Q2T, but these linecards are considered legacy and not recommended for IP Telephony and TelePresence deployments. For the full matrix of Catalyst 6500 queuing structures by module, refer to http://tinyurl.com/bgjkr5. |
Additionally, some switches support CoS-to-Queue mappings only (like the Catalyst 6500), others support either CoS- or DSCP-to-Queue mappings (like the Catalyst 2960, 3560 and 3750, and 4500 and 4900). Similarly, when it comes to dropping algorithms, some platforms support CoS-based WRED (Catalyst 6500), others support CoS- or DSCP-based Weighted-Tail Drop (WTD) (Catalyst 2960 and 3560 and 3750), or even platform-specific dropping algorithms, such as Dynamic Buffer Limiting (DBL) (Catalyst 4500 and 4900).
Long story short—network administrators need to be thoroughly familiar with the mapping, queuing, and dropping features of their Catalyst switches and linecard platforms to properly provision QoS policies within the campus.