SSO is a redundant route- and switch-processor availability feature that significantly reduces MTTR by allowing extremely fast switching between the main and backup processors. SSO is supported on routers (such as the Cisco 7600, 10000, and 12000 series families) and switches (such as the Catalyst 4500 and 6500 series families).
Prior to discussing the details of SSO, a few definitions might be helpful. For example, “state” in SSO refers to maintaining—among many other elements—the following between the active and standby processors:
Layer 2 protocols configurations and current status
Layer 3 protocol configurations and current status
Multicast protocol configurations and current status
QoS policy configurations and current status
Access list policy configurations and current status
Interface configurations and current status
Also, the adjectives cold, warm, or hot denote the readiness of the system and its components to assume the network services functionality and the job of forwarding packets to their destination. These terms appear in conjunction with Cisco IOS verification command output relating to NSF/SSO and with many high availability feature descriptions:
Cold: Cold redundancy refers to the minimum degree of resiliency that has been traditionally provided by a redundant system. A redundant system is cold when no state information is maintained between the backup or standby system and the system it offers protection to. Typically a cold system would have to complete a boot process before it came online and would be ready to take over from a failed system.
Warm: Warm redundancy refers to a degree of resiliency beyond the cold standby system. In this case, the redundant system has been partially prepared but does not have all the state information known by the primary system, so it can take over immediately. Some additional information must be determined or gleaned from the traffic flow or the peer network devices to handle packet forwarding. A warm system would already be booted up and would need to learn or generate only state information prior to taking over from a failed system.
Hot: Hot redundancy refers to a degree of resiliency where the redundant system is fully capable of handling the traffic of the primary system. Substantial state information has been saved, so the network service is continuous, and the traffic flow is minimally or not affected.
To better understand SSO, it might be helpful to consider its operation in detail within a specific context, such as within a Cisco Catalyst 6500 with two supervisors per chassis.
The supervisor engine that boots first becomes the active supervisor engine. The active supervisor is responsible for control-plane and forwarding decisions. The second supervisor is the standby supervisor, which does not participate in the control- or data-plane decisions. The active supervisor synchronizes configuration and protocol state information to the standby supervisor, which is in a hot-standby mode. As a result, the standby supervisor is ready to take over the active supervisor responsibilities if the active supervisor fails. This “take-over” process from the active supervisor to the standby supervisor is referred to as switchover.
Only one supervisor is active at a time, and supervisor-engine redundancy does not provide supervisor-engine load balancing. However, the interfaces on a standby supervisor engine are active when the supervisor is up and, thus, can be used to forward traffic in a redundant configuration.
NSF/SSO evolved from a series of progressive enhancements to reduce the impact of MTTR relating to specific supervisor hardware/software network outages. NSF/SSO builds on the earlier work known as
Route Processor Redundancy (RPR) and
RPR Plus (RPR+).
Each of these redundancy modes of operation incrementally improves upon the functions of the previous mode:
RPR: The first redundancy mode of operation introduced in Cisco IOS Software. In RPR mode, the startup configuration and boot registers are synchronized between the active and standby supervisors; the standby is not fully initialized; and images between the active and standby supervisors do not need to be the same. Upon switchover, the standby supervisor becomes active automatically, but it must complete the boot process. In addition, all line cards are reloaded, and the hardware is reprogrammed. Because the standby supervisor is “cold,” the RPR switchover time is 2 or more minutes.
RPR+: An enhancement to RPR in which the standby supervisor is completely booted, and line cards do not reload upon switchover. The running configuration is synchronized between the active and the standby supervisors, which run the same software versions. All synchronization activities inherited from RPR are also performed. The synchronization is done before the switchover, and the information synchronized to the standby is used when the standby becomes active to minimize the downtime. No link layer or control-plane information is synchronized between the active and the standby supervisors. Interfaces might bounce after switchover, and the hardware contents need to be reprogrammed. Because the standby supervisor is “warm,” the RPR+ switchover time is 30 or more seconds.
NSF with SSO: NSF works in conjunction with SSO to ensure Layer 3 integrity following a switchover. It allows a router experiencing the failure of an active supervisor to continue forwarding data packets along known routes while the routing protocol information is recovered and validated. This forwarding can continue to occur even though peering arrangements with neighbor routers have been lost on the restarting router. NSF relies on the separation of the control plane and the data plane during supervisor switchover. The data plane continues to forward packets based on pre-switchover Cisco Express Forwarding (CEF) information. The control-plane implements graceful restart routing protocol extensions to signal a supervisor restart to NSF-aware neighbor routers, reform its neighbor adjacencies, and rebuild its routing protocol database (in the background) following a switchover. Because the standby supervisor is “hot,” the NSF/SSO switchover time is 0 to 3 seconds.
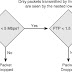
As previously described, neighbor nodes play a role in NSF function. A node that is capable of continuous packet forwarding during a route processor switchover is NSF-capable. Complementing this functionality, an NSF-aware peer router can enable neighbor recovery without resetting adjacencies and support routing database resynchronization to occur in the background. Figure 1 illustrates the difference between NSF-capable and NSF-aware routers. To gain the greatest benefit from NSF/SSO deployment, NSF-capable routers should be peered with NSF-aware routers (although this is not absolutely required for implementation) because only limited benefit will be achieved unless routing peers are aware of the capability of the restarting node to continue packet forwarding and assist in restoring and verifying the integrity of the routing tables after a switchover.

Cisco NSF and SSO are designed to be deployed together. NSF relies on SSO to ensure that links and interfaces remain up during switchover and that lower layer protocol state is
maintained. However, it is possible to enable SSO with or without NSF because these are configured separately.
The configuration to enable SSO is simple, as shown here:
NSF, on the other hand, is configured within the routing protocol and is supported within EIGRP, OSPF, IS-IS and (to an extent) BGP. Sometimes NSF functionality is also called “graceful-restart.”
To enable NSF for EIGRP, enter the following commands:
Similarly, to enable NSF for OSPF, enter the following commands:
Continuing the example, to enable NSF for IS-IS, enter the following commands:
And finally, to enable NSF/graceful-restart for BGP, enter the following commands:
You can see from the example of NSF that the line between device-level availability technologies and network availability technologies sometimes is blurry. A discussion of more network availability technologies follows.